Apache Spark 및 Spark API 소개
7 분 소요
아파치 스파크란?
- 범용적이면서도 빠른 속도로 작업을 수행할 수 있도록 설계한 클러스터용 연산 플랫폼
- MapReduce 모델을 대화형 명령어 query나 streaming 처리 등이 가능하도록 확장
- 기본적으로 연산을 메모리에서 수행하지만 디스크에서 돌리더라도 MapReduce보다 빠름
- Python, Java, Scala, SQL API 및 강력한 라이브러리 내장
- Hadoop 클러스터 위에서 실행 가능 (클러스터 매니저)
특징
- 속도: 스파크는 Hadoop 클러스터에서 디스크 읽기/쓰기 연산을 최소화하고 중간 처리 데이터를 메모리에 저장함으로써 메모리에서는 최대 100배, 디스크에서는 최대 10배 빠르게 어플리케이션을 수행 (반복 수행 성능 우수)
- 여러 언어 지원: 스파크는 Java, Scala, Python에서 내장 API를 지원하고 대화형 query를 위한 80개 이상의 고급 연산자도 제공
- 고급 분석: 스파크는 ‘Map’과 ‘Reduce’ 뿐만 아니라 SQL query, Streaming 데이터, 머신 러닝 그리고 Graph 알고리즘 또한 지원
구성 요소
Apache Spark Core
- 작업 스케줄링, 메모리 관리, 장애 복구, 저장 장치와의 연동 등등 기본적인 기능들로 구성
- RDD를 정의하는 API의 기반
- RDD는 여러 노드에 흩어져 있으면서 병렬 처리될 수 있는 아이템들의 모음을 표현
- 스파크 코어는 이 모음들을 생성하고 조작할 수 있는 수많은 API를 지원
Spark SQL
- 정형 데이터를 처리하기 위한 스파크의 패키지
- 스파크 SQL은 SQL뿐만 아니라 Hive 테이블, Parquet, JSON 등 다양한 데이터 소스를 지원
- 하이브의 HiveQL 사용 가능
- Python, Java, Scala의 RDD에서 지원하는 코드를 데이터 조작을 위해 SQL query와 함께 사용 가능
- Shark: 스파크 위에서 돌아갈 수 있도록 하이브를 수정한 SQL-on-Spark 프로젝트
Spark Streaming
- 실시간 데이터 스트림을 처리 가능하게 해 주는 스파크의 컴포넌트
- 데이터 스트림: 웹 서버가 생성한 로그 파일, 웹 서비스 사용자들이 만들어 내는 상태 업데이트 메시지들이 저장되는 큐 등
- 스파크 스트리밍은 스파크 코어의 RDD API와 거의 일치하는 형태의 데이터 스트림 조작 API를 지원
- 스파크 코어와 동일한 수준의 장애 관리, 처리량, 확장성을 지원하도록 설계
MLlib (Machine Learning Library)
- 스파크는 MLlib라는 일반적인 머신 러닝 기능들을 갖고 있는 라이브러리와 함께 배포
- MLlib는 분류, 회귀, 클러스터링, 협업 필터링 등의 다양한 타입의 머신 러닝 알고리즘 뿐만 아니라 모델 평가 및 외부 데이터 불러오기 같은 기능도 지원
- 게다가 경사 강하 최적화 알고리즘 같은 몇몇 저 수준의 ML 핵심 기능들도 지원
- 이 모든 기능들은 클러스터 전체를 사용하여 실행되도록 설계
GraphX
- 그래프X는 그래프를 다루기 위한 라이브러리이며 그래프 병렬 연산을 수행
- 스파크 스트리밍이나 스파크 SQL처럼 그래프X도 스파크 RDD API를 확장
- 각 간선(edge)이나 정점(vertex)에 임의의 속성을 추가한 방향성 그래프 생성 가능
- 또한, 그래프를 다루는 다양한 메소드들(subgraph, mapVertices) 및 일반적인 그래프 알고리즘들(page rank, triangle counting)의 라이브러리를 지원
클러스터 매니저
- 스파크는 하나의 노드부터 수천 노드까지 효과적으로 성능을 확장 가능
- 스파크는 Hadoop의 YARN, Apache Mesos, 스파크에서 지원하는 가벼운 구현의 클러스터 매니저인 Standalone 등 다양한 클러스터 매니저 위에서 동작
- 이미 YARN이나 Mesos 클러스터가 있다면 스파크는 그 위에서 앱을 실행시킬 수 있도록 지원
Resilient Distributed Datasets (RDD)
RDD란?
- Resilient: 메모리에서 데이터 손실 시 파티션을 재연산해 복구 가능
- Distributed: 클러스터의 모든 머신의 메모리에 분산 저장
- Datasets: 외부 파일 시스템과의 연동
- RDD는 스파크에서의 기본적인 데이터 단위: 변하지 않는, 분산된 레코드들의 집합
- Immutable: 생성 후 변경되지 않음 (read only)
- Partitioned: 데이터 세트를 분산
- RDD는 외부 데이터세트를 로드 하거나 드라이버 프로그램에서 객체 컬렉션(예: list, set)을 분산시키는 두 가지 방법 중의 하나로 생성 가능
- 스파크에서의 모든 작업은 새로운 RDD를 생성하거나 존재하는 RDD를 변형하거나 결과 계산을 위해 RDD 연산을 수행하는 것 중의 하나로 표현
- Lazy Execution: Action이 실행 되어야 실제 연산을 수행 (Transformation은 계보만 유지)
- 스파크의 RDD들은 기본적으로 action이 실행될 때마다 매번 새로 연산을 수행
- 만약 여러 액션에서 RDD 하나를 재사용하고 싶으면 스파크에게
RDD.persist()를 사용하여 계속 결과를 유지할 수 있도록 요청 가능
파티션
- 하나의 RDD는 여러 개의 파티션으로 나뉘어짐
- 파티션의 개수, 파티셔너(hash, range, 사용자 정의) 선택 가능
- 종속성 유형
- Narrow Dependencies: 변환 후의 파티션이 하나의 파티션으로 매핑
- Wide Dependencies: 변환 후의 파티션이 여러 파티션으로 매핑
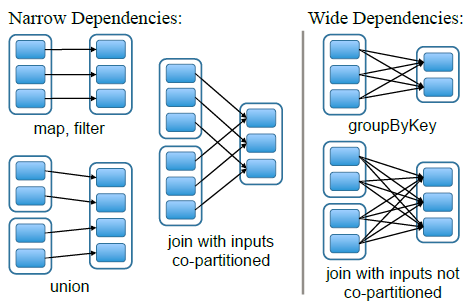 종속성 유형: Narrow and wide dependencies
종속성 유형: Narrow and wide dependencies
RDD 연산
- RDD는 두 가지 타입의 연산 작업, 즉 Transformation과 Action을 지원
- Transformation은
map()이나 filter()처럼 새로운 RDD를 생성하는 연산
- Action은 드라이버 프로그램에 결과를 되돌려 주거나 스토리지에 결과를 써 넣는 연산
count(), first() 같이 실제 계산을 수행
Spark API
워드 카운트
text_file = sc.textFile("hdfs://...")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://...")
Pi 예측
def inside(p):
x, y = random.random(), random.random()
return x*x + y*y < 1
count = sc.parallelize(xrange(0, NUM_SAMPLES)) \
.filter(inside).count()
print "Pi is roughly %f" % (4.0 * count / NUM_SAMPLES)
- Transformation은 주로 존재하는 RDD에서 새로운 RDD를 생성하는 연산
- RDD는 읽기 전용, 따라서 기존 RDD에서 새로운 RDD를 생성
- log.txt 파일에서 에러 메시지만 선택하여 가져오기
- 스파크는 각 RDD에 대해 가계도(lineage graph)라 불리는 관계 그래프를 가짐
- 스파크는 이 정보를 필요 시 각 RDD를 재연산하거나 저장된 RDD가 유실될 경우 복구를 하는 등의 경우에 활용
- Fault-tolerant: 계보(lineage)만 기록해두면 동일한 RDD 생성 가능
- RDD의 replications 관리 비용 보다 계보의 관리 비용이 더 저렴
- 일부 계산 비용이 크고 재사용되는 RDD는 check pointing 활용
Map
- RDD의 각 요소에 함수를 적용하고 결과 RDD를 반환
x = sc.parallelize(["b", "a", "c"])
y = x.map(lambda z: (z, 1))
print(x.collect())
print(y.collect())
x: ['b', 'a', 'c']
y: [('b', 1), ('a', 1), ('c', 1)]
Filter
filter()로 전달된 함수의 조건을 통과한 값으로만 이루어진 RDD를 반환
x = sc.parallelize([1, 2, 3])
y = x.filter(lambda x: x % 2 == 1) # 홀수만 유지
print(x.collect())
print(y.collect())
FlatMap
- RDD의 각 요소에 함수를 적용하고 반환된 반복자의 내용들로 이루어진 RDD를 반환 $\rightarrow$ 단어 분해 용도
x = sc.parallelize([1, 2, 3])
y = x.flatMap(lambda x: (x, x * 100, 42))
print(x.collect())
print(y.collect())
x: [1, 2, 3]
y: [1, 100, 42, 2, 200, 42, 3, 300, 42]
GroupBy
x = sc.parallelize(['John', 'Fred', 'Anna', 'James'])
y = x.groupBy(lambda w: w[0])
print([(k, list(v)) for (k, v) in y.collect()])
x: ['John', 'Fred', 'Anna', 'James']
y: [('A', ['Anna']), ('J', ['John', 'James']), ('F', ['Fred'])]
GroupByKey
x = sc.parallelize([('B', 5), ('B', 4), ('A', 3), ('A', 2), ('A', 1)])
y = x.groupByKey()
print(x.collect())
print(list((j[0], list(j[1])) for j in y.collect()))
x: [('B', 5), ('B', 4), ('A', 3), ('A', 2), ('A', 1)]
y: [('A', [2, 3, 1]), ('B', [5, 4])]
ReduceByKey vs. GroupByKey
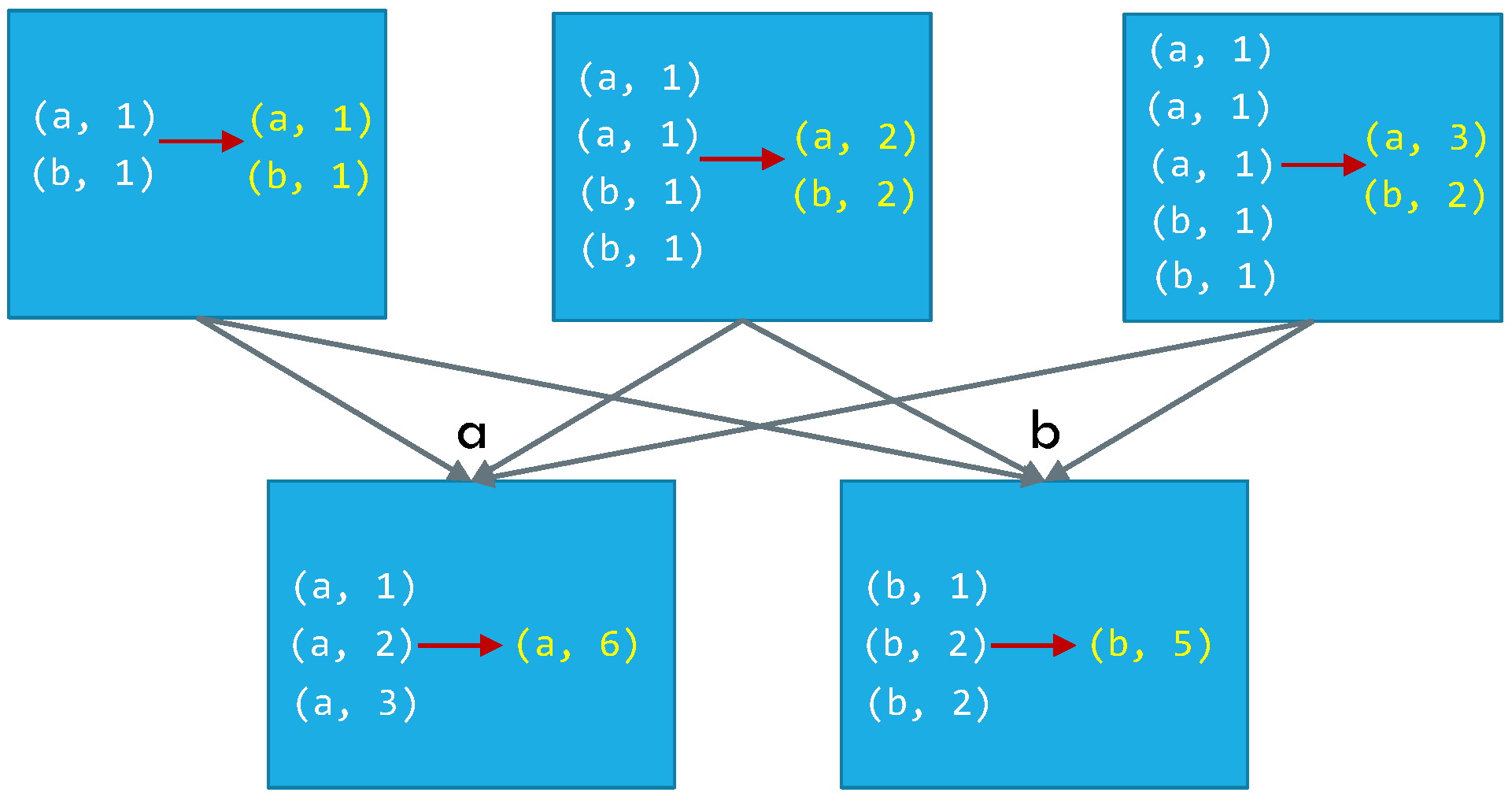 ReduceByKey
ReduceByKey
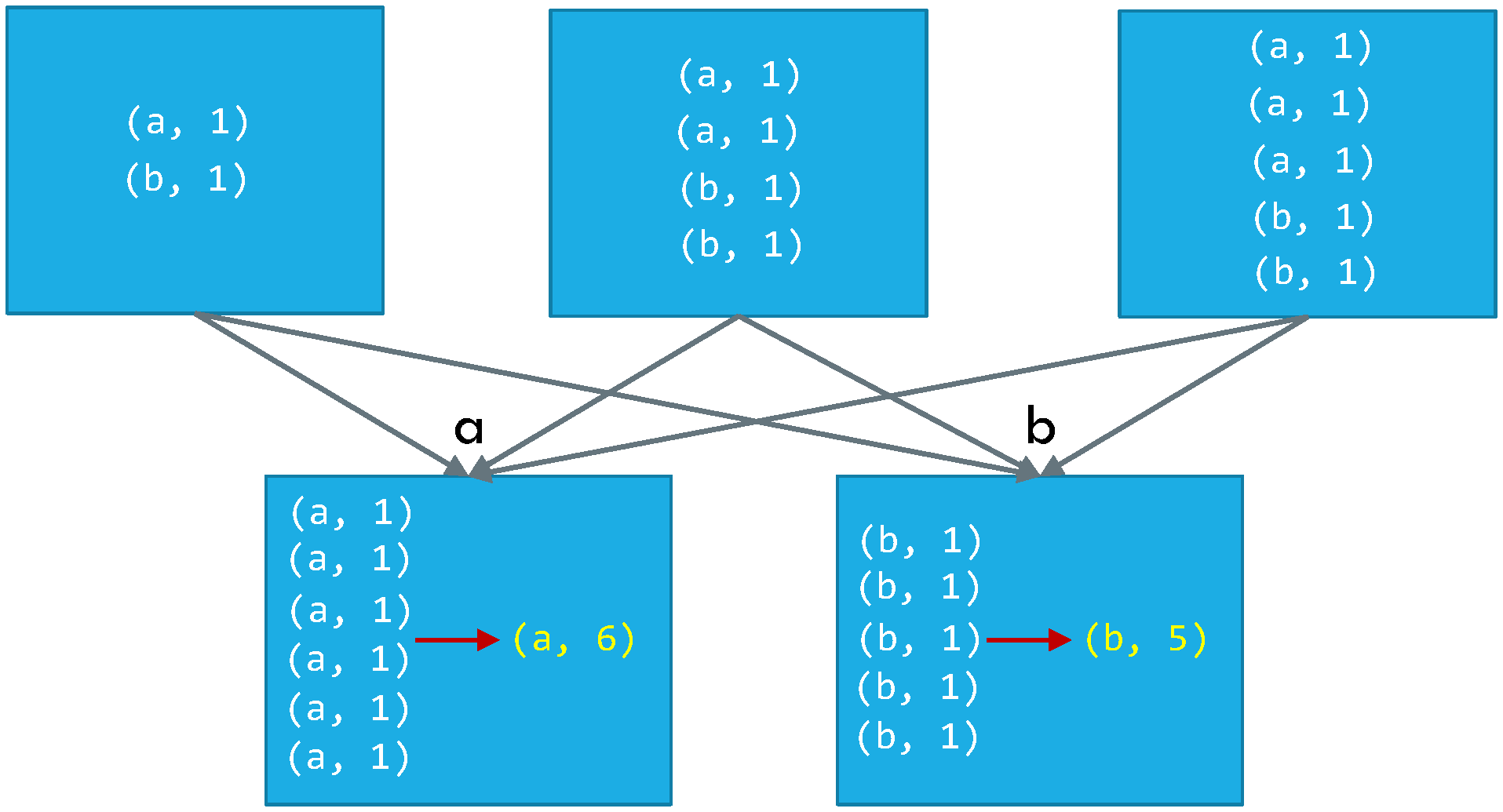 GroupByKey
GroupByKey
MapPartitions
def f(iterator): yield sum(iterator); yield 42
x = sc.parallelize([1, 2, 3], 2) # [[1], [2, 3]]
y = x.mapPartitions(f)
print(x.glom().collect()) # glom()을 사용하여 원소들을 파티션별로 구별하여 출력
print(y.glom().collect())
x: [[1], [2, 3]]
y: [[1, 42], [5, 42]]
MapPartitionsWithIndex
def f(partitionIndex, iterator): yield (partitionIndex, sum(iterator))
x = sc.parallelize([1, 2, 3], 2)
y = x.mapPartitionsWithindex(f)
print(x.glom().collect())
print(y.glom().collect())
x: [[1], [2, 3]]
y: [[0, 1], [1, 5]]
Sample
x = sc.parallelize([1, 2, 3, 4, 5])
y = x.sample(False, 0.4, 42) # sample(withReplacement, fraction, seed=None)
print(x.collect())
print(y.collect())
x: [1, 2, 3, 4, 5]
y: [1, 3]
Union
- 두 RDD에 있는 데이터들을 합한 RDD를 생성
x = sc.parallelize([1, 2, 3], 2)
y = sc.parallelize([3, 4], 1)
z = x.union(y)
print(x.collect())
print(y.collect())
print(z.glom().collect())
x: [1, 2, 3]
y: [3, 4]
z: [[1], [2, 3], [3, 4]]
Join
x = sc.parallelize([("a", 1), ("b", 2)])
y = sc.parallelize([("a", 3), ("a", 4), ("b", 5)])
z = x.join(y)
print(x.collect())
print(y.collect())
print(z.collect())
x: [("a", 1), ("b", 2)]
y: [("a", 3), ("a", 4), ("b", 5)]
z: [('a', (1, 3)), ('a', (1, 4)), ('b', (2, 5))]
Distinct
x = sc.parallelize([1, 2, 3, 3, 4])
y = x.distinct()
print(x.collect())
print(y.collect())
x: [1, 2, 3, 3, 4]
y: [1, 2, 3, 4]
Coalesce
x = sc.parallelize([1, 2, 3, 4, 5], 3)
y = x.coalesce(2)
print(x.glom().collect())
print(y.glom().collect())
x: [[1], [2, 3], [4, 5]]
y: [[1], [2, 3, 4, 5]]
KeyBy
x = sc.parallelize(['John', 'Fred', 'Anna', 'James'])
y = x.keyBy(lambda w: w[0])
print(x.collect())
print(y.collect())
x: ['John', 'Fred', 'Anna', 'James']
y: [('J', 'John'), ('F', 'Fred'), ('A', 'Anna'), ('J', 'James')]
PartitionBy
x = sc.parallelize([('J', 'James'), ('F', 'Fred'), ('A', 'Anna'), ('J', 'John')], 3)
y = x.partitionBy(2, lambda w: 0 if w[0] < 'H' else 1)
print(x.glom().collect())
print(y.glom().collect())
x: [[('J', 'James')], [('F', 'Fred')],
[('A', 'Anna'), ('J', 'John')]]
y: [[('A', 'Anna'), ('F', 'Fred')],
[('J', 'James'), ('J', 'John')]]
Zip
x = sc.parallelize([1, 2, 3])
y = x.map(lambda n: n * n)
z = x.zip(y)
print(x.collect())
print(y.collect())
print(z.collect())
x: [1, 2, 3]
y: [1, 4, 9]
z: [(1, 1), (2, 4), (3, 9)]
Actions
- 액션은 드라이버 프로그램에 최종 결과 값을 되돌려 주거나 외부 저장소에 값을 기록하는 연산 작업
- 액션은 실제로 결과 값을 내어야 하므로 트랜스포메이션이 계산을 수행하도록 강제
GetNumPartitions
x = sc.parallelize([1, 2, 3], 2)
y = x.getNumPartitions()
print(x.glom().collect())
print(y)
Collect
x = sc.parallelize([1, 2, 3], 2)
y = x.collect()
print(x.glom().collect())
print(y)
x: [[1], [2, 3]]
y: [1, 2, 3]
Reduce
x = sc.parallelize([1, 2, 3, 4])
y = x.reduce(lambda a, b: a + b)
print(x.collect())
print(y)
Aggregate
seqOp= lambda data, item: (data[0] + [item], data[1] + item)
combOp= lambda d1, d2: (d1[0] + d2[0], d1[1] + d2[1])
x = sc.parallelize([1, 2, 3, 4])
y = x.aggregate(([], 0), seqOp, combOp)
print(x.collect())
print(y)
x: [1, 2, 3, 4]
y: ([1, 2, 3, 4], 10)
Max
x = sc.parallelize([2, 4, 1])
y = x.max()
print(x.collect())
print(y)
Sum
x = sc.parallelize([2, 4, 1])
y = x.sum()
print(x.collect())
print(y)
Mean
x = sc.parallelize([2, 4, 1])
y = x.mean()
print(x.collect())
print(y)
x: [2, 4, 1]
y: 2.3333333
Stdev
x = sc.parallelize([2, 4, 1])
y = x.stdev()
print(x.collect())
print(y)
x: [2, 4, 1]
y: 1.2472191
CountByKey
x = sc.parallelize([('J', 'James'), ('F', 'Fred'), ('A', 'Anna'), ('J', 'John')])
y = x.countByKey()
print(x.collect())
print(y)
x: [('J', 'James'), ('F','Fred'), ('A', 'Anna'), ('J', 'John')]
y: {'A': 1, 'J': 2, 'F': 1}
SaveAsTextFile
dbutils.fs.rm("/temp/demo", True)
x = sc.parallelize([2, 4, 1])
x.saveAsTextFile("/temp/demo")
y = sc.textFile("/temp/demo")
print(y.collect())
x: [2, 4, 1]
y: [u'2', u'4', u'1']
References

댓글남기기